


Got images or PDF files and want to recognize plain text from them? It’s easy to do the job via Tesseract OCR and a graphical tool is available for beginners.
For Linux, e.g., Ubuntu, Debian, Fedora, and Arch Linux, Tesseract OCR is a Free and Open-Source popular solution for extracting text from a scanned PDF document or an image. And gImageReader is the graphical front-end to make life easier for those hate Linux commands.
Tesseract OCR and gImageReader
OCR stands for optical character recognition or optical character reader. It is a computer technology to convert images of handwritten or printed text into machine-encoded text. Whether from a scanned document, a photo of a document, or subtitle text on an image.
Tesseract is one of the most accurate open-source OCR engines that works on Windows, Linux, and macOS. It was originally developed by HP as a proprietary software, and later released as open-source project and sponsored by Google. And it can read more than 120 languages.
The software runs in command line which is not friendly for beginners. So graphical UI tools born, and gImageReader is one of them that works on Linux.
Install gImageReader & Tesseract OCR
The open-source projects are available in official repositories for most Linux distributions. You can install them as easy as running a few commands in terminal.
Install gImageReader & Tesseract OCR in Ubuntu / Debian / Linux Mint:
For apt-based Linux system, firstly open terminal from start menu.
Then copy and paste the command below into terminal and hit Enter.
sudo apt install gimagereader
It installs gimagereader as well as Tesseract OCR library as dependency package with your system language support.
If you want another language support, e.g, German and/or Greek, install them via:
sudo apt install tesseract-ocr-deu tesseract-ocr-ell
Or just run command to install the package with ALL language support:
sudo apt install tesseract-ocr-all
Install gImageReader & Tesseract OCR in Fedora / Arch Linux:
For Fedora and Arch Linux, the package name is gimagereader-gtk instead. You can open “terminal” and run command to install it:
sudo dnf install gimagereader-gtk
sudo pacman -S gimagereader-gtk
Tesseract will be installed as well with your system language support. You can add more language support, e.g., German and Greek, by installing tesseract-ocr-deu and tesseract-ocr-ell. Or install tesseract-ocr-* for ALL languages.
Export Plain Text via gImageReader:
Once you installed the tool, search for and open it from your system start menu.
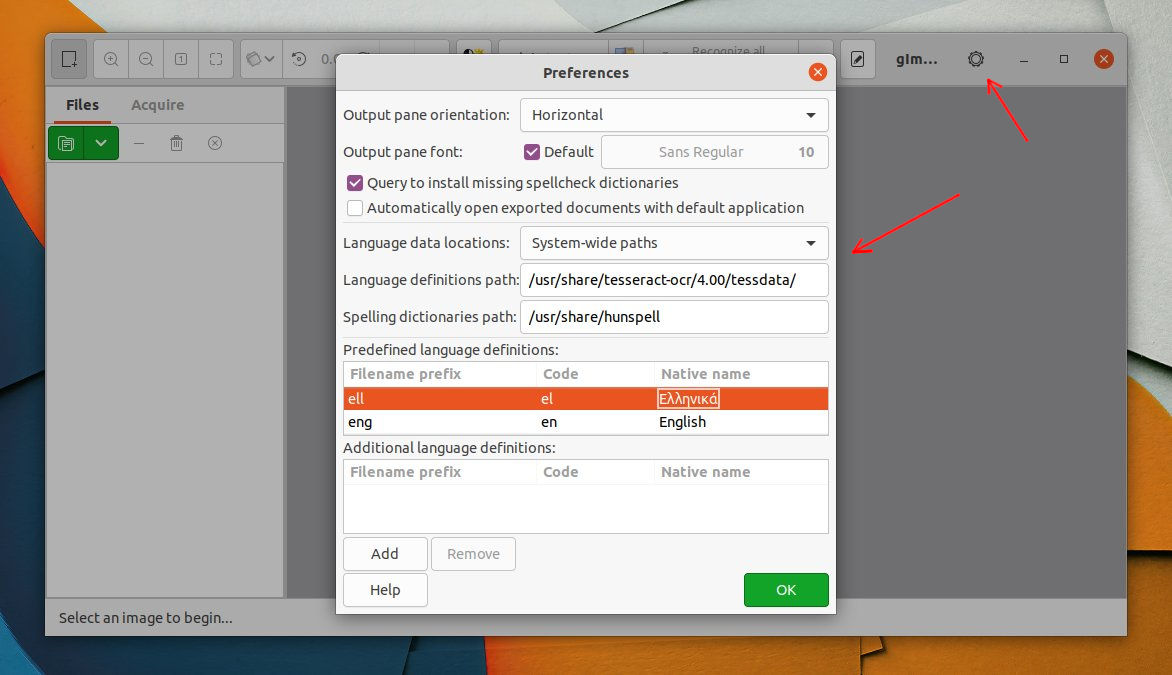
When it starts, click the top-right ‘gear‘ button to open the software “Preferences” dialog. There you can do:
- set the output pane position: bottom (Horizonal) or right-side (Vertical).
- change the output font.
- select language data path. Default is usually OK.
- choose predefined language.
Now click on green button in left pane to import an image or PDF. Or acquire from your scanner. Choose output “Plan Text” or “hOCR PDF”. And select an area in file preview that you want to convert, or let it go for full page without selection.
There are some other actions, e.g., zoom in/out, rotate, select pages. To make the photo image easy to read, you can even control the brightness, contrast, and resolution.
Via the down arrow after “Recognize all/section” button, it offers options to choose another language, multi-language, add whitelist / backlist, and a few other actions.
In the output pane, there are a few buttons to strip line breaks, find and replace, redo/undo, clear text, as well as the icon to export to TXT document.
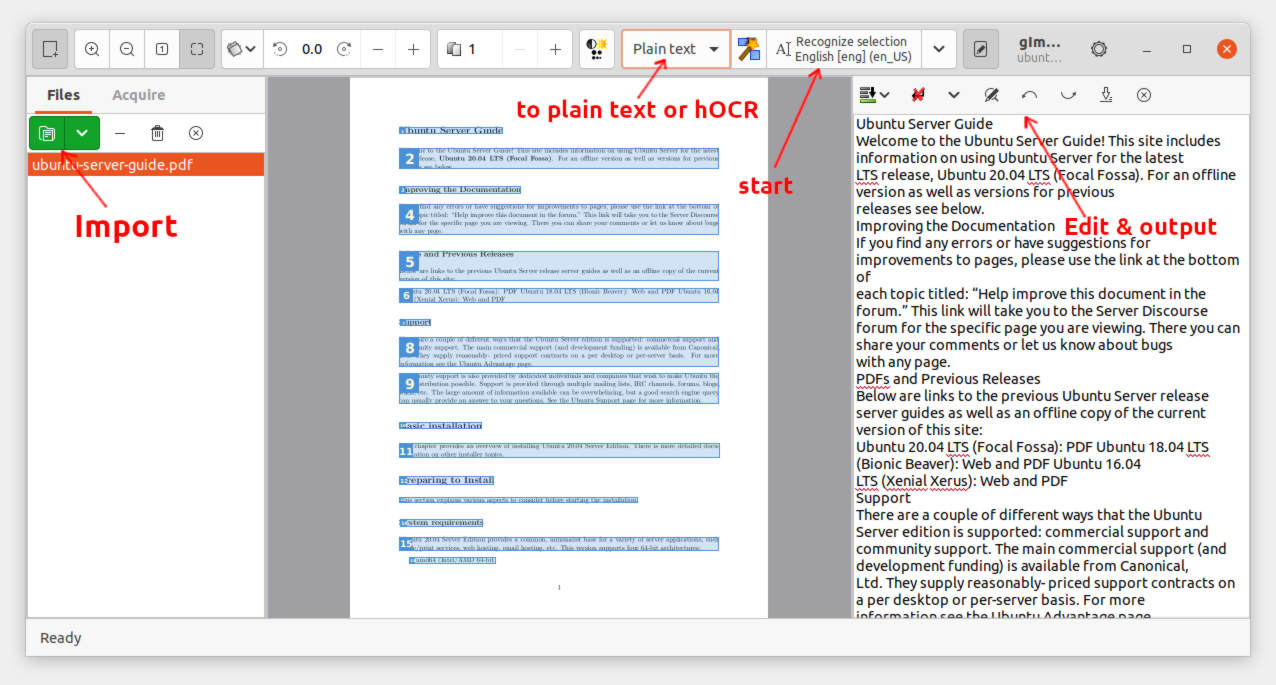
The software is easy to use since it provides tool-tips support. Just hover the mouse pointer over an icon, a little pop-up will indicate what does it do.
For bugs and more about the tool, go to the github project page.